爱阅书香配置微软tts听书 Docker自建版(Edge 大声朗读接口)
系列文章
- 1. 更方便地导入微软 TTS 听书:阅读、爱阅书香、源阅读(Azure 官方/试用接口)
- 2. 源阅读配置微软 TTS 听书(Edge 大声朗读接口)
- 3. 爱阅听书 微软TTS Vercel部署教程(Edge 大声朗读)
- 4. 爱阅书香配置微软tts听书 Docker自建版(Edge 大声朗读接口)
通过 Docker 部署的免费听书服务,使用微软 Edge 的大声朗读接口,可以使用晓晓、云希等音色听书。
2024/02/05 更新:可以一键导入爱阅记了!同时,如果采用 Docker 部署,现在有了原生的镜像并且缩减了镜像大小。
Tip
阅读本文前,可以先看一看我的 听书方法整理汇总 哦🤗
前言
Tip
对于不想折腾的朋友,通过 Vercel 部署可能更方便。详见 爱阅书香听书微软 AI 语音 TTS Vercel 部署教程
对于有 Azure TTS API 的朋友,可以看一看 使用官方 API:创建资源、导入软件 这篇文章中的这个小标题,或者直接去 https://tts-importer.yfi.moe 便捷地将听书配置导入阅读、爱阅记、源阅读软件。
- docker 实现
- 项目地址 yy4382/ms-ra-forwarder-for-ifreetime
- 由 wxxxcxx/ms-ra-forwarder: 免费的在线文本转语音API (github.com) 修改而来,记得给大佬点个 star
- 特别感谢 @justnsms 大佬写的代码,没有他的帮助,肯定不可能有这么方便的方法
- 配置过程中出问题的可以给我发邮件(邮箱在博客侧边栏)
前置条件
- 有一台可以运行 Docker 的机器
- 安装好 docker
参考这篇文章的安装 Docker 一节:安装 Docker
安装服务器端
安装
# 创建文件夹,名字任意
mkdir ifreetime_tts&&cd ifreetime_tts
# 下载文件
wget https://gist.github.com/yy4382/d0c2a5e2c19323f4aa651f99317fd53e/raw/docker-compose.yml
# 启动容器
docker compose up -d
# 搞好了!按照下文的方法验证是否成功,然后在爱阅中配置听书想要设置 token 的话,按照 yaml 文件里的注释操作
更新
先 cd 进 docker-compose.yml 所在文件夹
docker compose pull
docker compose up -d配置 ios 端爱阅书香
参考 Vercel 部署教程 爱阅配置部分,唯一的区别在于地址,应该是
http://ip:3000/api/aiyue
有问题评论讲
附:早期版本
Note
这是我最初做的版本,挺复杂的,仅供参考
- 需要两个服务,一个是 tts 文字转语音服务,如果只要安卓的阅读 3.0 使用,只要这个就可以了;另一个是将第一个服务转换成爱阅书香可以使用的格式
- 两个项目的地址:wxxxcxx/ms-ra-forwarder: 免费的在线文本转语音API (github.com) ,iranee/ifreetime: iOS爱阅书香TTS自建服务 (github.com),记得给两位大佬点 star
稍显麻烦,需要 docker 基础知识,但是可以让你知道这一切是如何运作的,放在文末了
ms-ra-forwarder
- GitHub 地址:wxxxcxx/ms-ra-forwarder: 免费的在线文本转语音API (github.com)
- 项目本身提供了
docker-compose.yml文件,直接用就是了 - 打开
http://你的ip:3000看看是否有这个页面
也可以用 vercel,但是每月只有 100G 免费流量,听的多的/还搭了其他服务的要小心些
- 因为微软把 Azure 的试用关了,所以只能用 ra(edge 的大声朗读)接口了
ifreetime
- 项目地址:iranee/ifreetime: iOS爱阅书香TTS自建服务 (github.com)
- 如果你的服务器已经在运行一个支持 php 的网站了,直接把项目里的
ra.php中的http://127.0.0.1:3000/api/ra的 ip 改成你自己在第一步里用的,然后丢到网站里就行 - 如果没有,那么需要建一个 docker 容器以运行该 php 文件(警告:我没写过 php,dockerfile 的写法是 ChatGPT 给的,不保证最优,但应该能用,反正我成功了)
-
新建一个文件夹,假设叫做 ifreetime(其他的也行)
-
进入文件夹,再建一个叫做 src 的文件夹,把项目中的 ra.php 放进去(或者直接把整个项目 clone 进去也行)
-
修改 ra.php,把
http://127.0.0.1:3000/api/ra中的127.0.0.1:3000换成第一步中生成的 ip+ 端口- 对于服务器,最方便的方法是直接用公网 ip+ 端口,对于群晖,最简单的是用局域网 ip+ 端口
- 经测试可行的其他替代方案:
- 云服务器做好域名解析和反代之后,使用类似
https://tts.example.com/api/ra的格式(使用https://tts.example.com可以访问 ms-ra-forwarder) - 使用本地 docker 的 ip,一般是 172.17.0.1,所以应该形如
http://172.17.0.1:3000/api/ra
- 云服务器做好域名解析和反代之后,使用类似
- 不可行的方案: 不可以使用 127.0.0.1,因为在容器里
- 可能会出问题的方案:域名 + 端口的形式,比如
https://www.example.com:3000/api/ra尤其对于 nas 来说,因为 80/443 没法用,所以不得不额外加端口。有人这样搞失败了,但不确定是不是因为这个问题。有人这样搞成功了的话,用邮件踢我一脚(邮箱在博客上有写)
-
回到 ifreetime 文件夹,新建一个叫
Dockerfile的文件,内容为# 设置基础镜像 FROM php:7.3 # 将本地代码复制到容器中的 /var/www/html 目录 COPY src/ /var/www/html/ # 设置容器内的工作目录 WORKDIR /var/www/html # 暴露容器的 8000 端口 EXPOSE 8000 #启动php服务器 CMD ["php", "-S", "0.0.0.0:8000"] -
构建并运行:在 ifreetime 目录中,依次输入如下指令
docker build -t ifreetime . docker run -d -p 12222:8000 ifreetime -
这种方法,需要将爱阅中的配置(还有测试的时候)把 3000 都换成 12222.而且/api/aiyue 都换成/ra.php
-
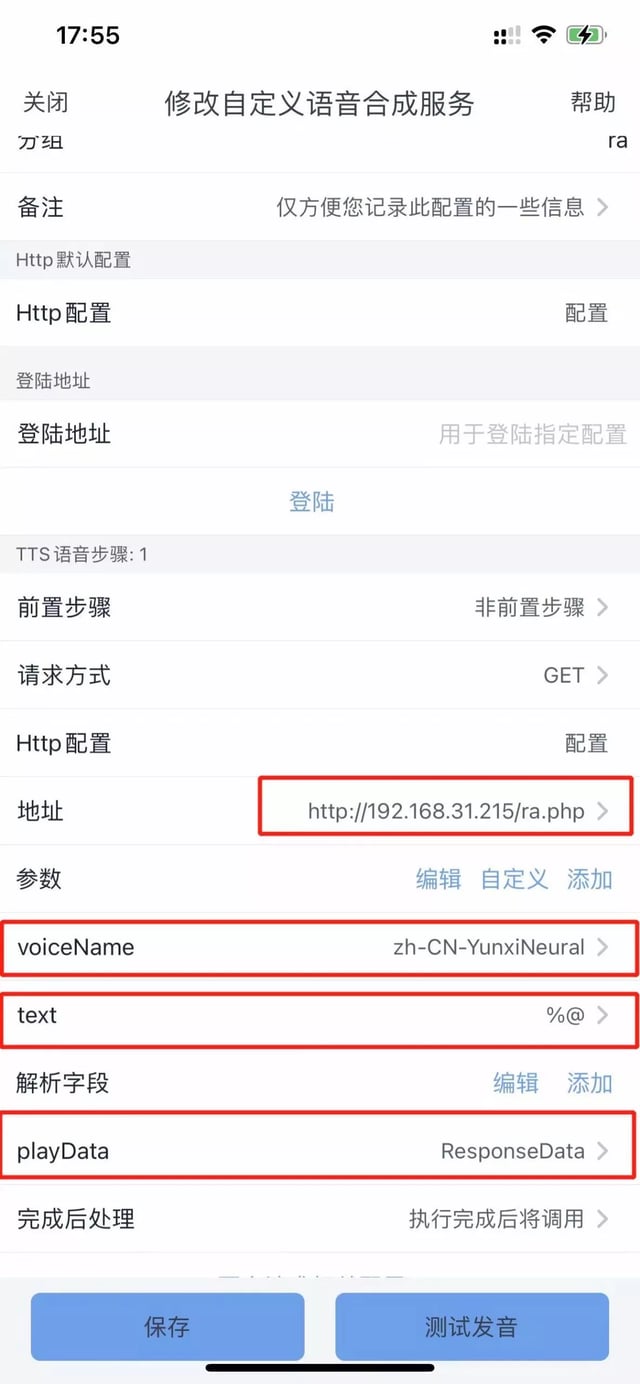
打开手机 App,进入听书配置 -> 自定义语音库 创建 ->高级自定义语音合成
名称:任意
合成字数:建议 200
请求方式:GET
地址:ra.php 网络地址,如果安装上面的方法,是
http://你的ip:12222/ra.php参数 ->添加 ->请输入请求参数:voiceName,内容填自己想要的人声(参考 这里),例如 zh-CN-XiaoxiaoNeural
参数 ->添加 ->请输入请求参数:text,内容填%@
解析字段 ->添加 ->请输入解析字段与规则:playData,内容填 ResponseData
测试发音,如果正确就 ok 了。
本文使用“署名-非商业性使用-相同方式共享 4.0 国际(CC BY-NC-SA 4.0)”进行许可。
商业转载请联系站长获得授权,非商业转载请注明本文出处及文章链接。 如果您再混合、转换或者基于本作品进行创作,您必须基于相同的协议分发您贡献的作品。
系列文章
- 1. 更方便地导入微软 TTS 听书:阅读、爱阅书香、源阅读(Azure 官方/试用接口)
- 2. 源阅读配置微软 TTS 听书(Edge 大声朗读接口)
- 3. 爱阅听书 微软TTS Vercel部署教程(Edge 大声朗读)
- 4. 爱阅书香配置微软tts听书 Docker自建版(Edge 大声朗读接口)